The World’s Biggest Landfill Is Invisible — And You’re Filling It Right Now
How the “record everything” culture is burying us in data we never use — and costing us the planet in the process.


You woke up this morning, and before your feet hit the floor, you had already generated data. Your smartwatch logged your sleep cycles. Your doorbell camera captured three passing cars and a squirrel. Your phone backed up overnight photos to the cloud. Your smart thermostat reported the temperature every fifteen minutes to a server farm — somewhere in Virginia, probably — that dutifully stored each reading alongside billions of others, most of which no human will ever look at.
By the time you finish reading this article, the world will have created roughly 1.7 million terabytes of new data. That is not a typo. And here is the part that should keep you up at night: the vast majority of it — somewhere between 68% and 90%, depending on who you ask — will never be accessed, analyzed, or even glanced at again.
We are building the largest landfill in human history. You just cannot see it.
So how did we get here?
Let me give you some numbers — not to overwhelm you, but because the scale of the problem is genuinely hard to grasp without them.
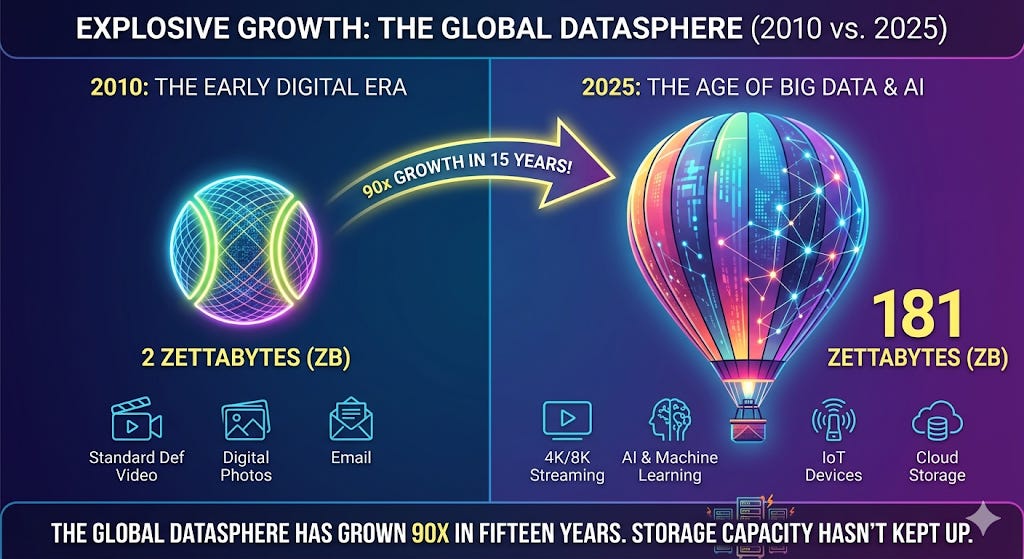
In 2010, humanity collectively produced about 2 zettabytes of data for the entire year. A zettabyte, if you are wondering, is a trillion gigabytes — roughly enough storage to hold 250 billion DVDs. All is good so far; 2 zettabytes sounds manageable.
By 2020, that number had exploded to 64 zettabytes. Then the pandemic hit, everyone went remote, and data creation spiked 57% in a single year. Today, in 2026, we are generating north of 400 million terabytes every single day. IDC — the global market intelligence firm that tracks these things — projects the global datasphere will reach 527 zettabytes by 2029. Their Senior VP Dave Reinsel put it bluntly: the data created in the next five years will exceed twice the total created since digital storage was invented.
Here is where things get interesting — and troubling. We cannot actually store most of it. In 2020, the world had roughly 6.7 zettabytes of total storage capacity for 64 zettabytes of data created. That is a 10-to-1 ratio. The National Academies projects that reaching 1,000 zettabytes of storage by 2040 would cost somewhere between $50 and $100 trillion. So we cannot save everything even if we wanted to.
And yet — we keep trying.
The digital hoarders
Here is an analogy that might hit home. You know that person (maybe it is you — no judgment) who keeps every single receipt, every birthday card, every expired coupon, stuffed in drawers and shoeboxes throughout the house? Now imagine that hoarding habit, but applied to every organization and individual on Earth, at industrial scale, with real environmental consequences.
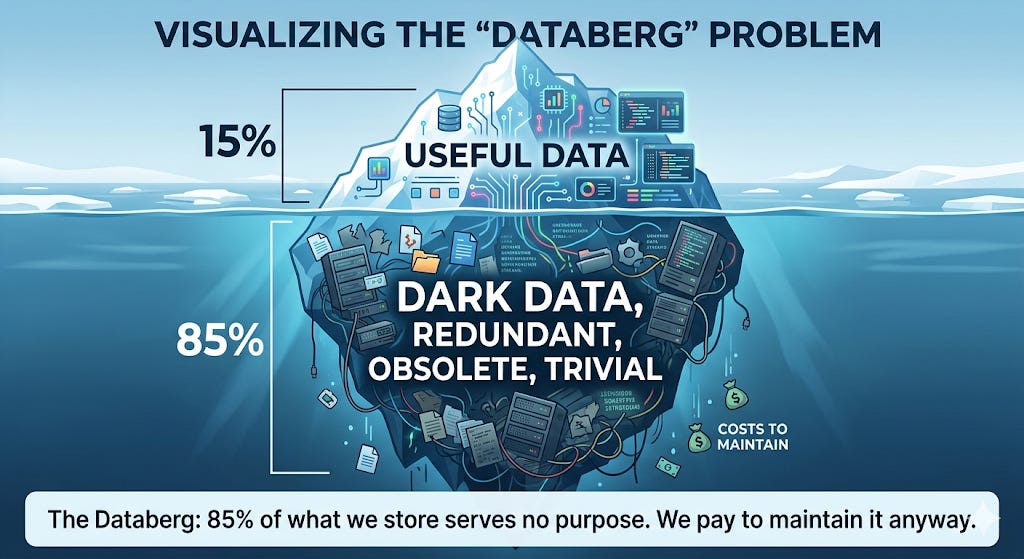
Veritas Technologies surveyed 2,550 IT decision-makers across 22 countries and found that 85% of all stored data is either “dark” (never analyzed, never used, purpose unknown) or ROT — redundant, obsolete, trivial. Fifty-two percent was dark. Thirty-three percent was outright junk. Only 15% of everything companies stored was actually business-critical. Gartner pegs the dark data figure even higher, at 80–90%.
McKinsey & Company estimates that 30–40% of daily business reports add little to no value — many are duplicative, others simply go unread. A separate McKinsey analysis suggests only 1% of all generated data has ever been analyzed. One percent. The rest just sits there, consuming electricity, radiating heat, demanding cooling water.
Why? Because storage got cheap, and deleting things feels risky. So the default became: keep everything, forever, just in case. As one industry analyst observed, the average business server delivers only 5–15% of its computing capacity. The Uptime Institute found nearly 30% of servers worldwide sit completely idle — roughly 10 million machines humming away at a cost of $30 billion per year, doing absolutely nothing.
The machines that never blink
So far so good — or rather, so far so bad. But here is where the story really accelerates.
The explosion is not just about people posting selfies (though Instagram alone sees 95 million photos and videos per day, and YouTube receives 500 hours of video every minute). The real driver is the proliferation of machines that record constantly, by design, whether anyone is watching or not.
There are now over 18.5 billion connected IoT devices globally — smart doorbells, dashcams, wearables, industrial sensors, connected appliances — projected to hit 39 billion by 2030. The smart home security camera market alone is expected to grow from roughly $11 billion today to over $50 billion by 2033. In the U.S., 42% of households already have home video surveillance. Your doorbell camera — that little device you bought for package theft peace of mind — can easily consume 2–3 gigabytes of data per day, most of it footage of empty porches and passing clouds.
And it is about to get far worse.
A single autonomous vehicle generates roughly 4 terabytes of data per hour from its cameras, LiDAR, and radar. Most of it — perhaps 99.99% — captures utterly mundane driving. Always-on wearables are normalizing continuous recording of your entire life: Limitless AI (recently acquired by Meta) sells a pendant that records your conversations 24/7, storing 35 hours locally before offloading to the cloud. And AI-generated content is flooding the supply side — projections suggest AI-produced material could constitute up to 99% of internet content by 2030.
Just imagine that for a moment. Machines generating data that is stored by other machines, analyzed by yet other machines, most of it created by AI and consumed by no one. A closed loop of digital waste with a very real energy bill.
The bill comes due — in watts, water, and waste
This is where the conversation shifts from abstract to urgent. Data does not float in some ethereal “cloud.” It lives in physical buildings full of servers that consume staggering amounts of energy and water.
The International Energy Agency reports that global data centers consumed 415 terawatt-hours of electricity in 2024 — roughly 1.5% of all electricity generated on Earth. That is more than many entire countries use. By 2030, the IEA projects this will reach 945 TWh — equivalent to Japan’s total electricity consumption and roughly 3% of global supply. In Ireland, data centers already draw 21% of the national grid — more than all urban households combined. In the United States, data centers consume over 4% of total electricity and are on track to surpass all energy-intensive manufacturing — aluminum, steel, cement, chemicals — combined by 2030.
Then there is water. Servers generate enormous heat and need cooling, and many cooling systems rely on evaporating vast quantities of fresh water. Lawrence Berkeley National Laboratory found U.S. data centers directly consumed 17 billion gallons of water for cooling in 2023 — and indirect consumption (through power generation) was 12 times that. A single major facility in Iowa consumed one billion gallons in a single year — enough to supply the state’s residential water for five days.
And the carbon? Global data center emissions stand at approximately 180 million tonnes of CO₂ annually. Researcher Jens Malmodin at Ericsson — who conducted the most rigorous assessment to date, covering data from about 100 major global operators — puts the broader ICT sector’s footprint at roughly 730 million tonnes CO₂-equivalent, approaching aviation’s ~800 million tonnes. Some researchers at Lancaster University argue the true figure could be 2–4% of global emissions when full lifecycle impacts are included.
And we have not even mentioned e-waste. A 2024 study in Nature Computational Science projected that generative AI alone could produce 1.2 to 5 million metric tonnes of electronic waste by 2030. Server hardware has a lifespan of 3–5 years; in the U.S., 20–70 million hard drives reach end-of-life annually, with most shredded and sent to landfills. The physical ones, this time.

What does this mean for you?
You might be thinking: I am just one person. My Ring doorbell and iCloud photos are a drop in the ocean. And in isolation, you would be right. But this is a collective action problem — and the defaults are set against us.
Every app, every device, every platform is designed to capture and store more, not less. Cloud storage plans auto-upgrade. Cameras default to continuous recording. Social platforms incentivize posting and never deleting. Your phone backs up every screenshot, every accidental photo of the inside of your pocket. The friction to create and store data is zero. The friction to review, curate, or delete it is enormous.
Federica Lucivero of the University of Oxford framed it well in her 2020 paper: data consumption is no less environmentally problematic than material goods consumption. The paperless office did not save us — it just moved the waste somewhere we cannot see it.
Tom Jackson of Loughborough University puts it more bluntly: more than half the data firms collect is for single-use purposes and never touched again. His colleague Hanlie Smuts at the University of Pretoria estimates dark data alone generates over 5.8 million tonnes of CO₂ annually — the equivalent of 1.2 million cars.
Now imagine 2035
Let me paint you a picture of where we are headed if nothing changes — and I want you to sit with this one.
It is 2035. Every new car sold has 12 cameras and continuous LiDAR, generating 20 terabytes per day, whether it drives itself or not. Your smart glasses record every conversation and every face you see, uploading continuously to servers that process, store, and index it all — because the business model depends on it. Your children’s schools have AI-powered surveillance monitoring hallways, classrooms, and playgrounds around the clock. Your hospital visit generates a gigabyte of imaging data that is stored in triplicate across three data centers on two continents — because regulations require retention, and nobody wrote regulations requiring deletion.
AI systems, meanwhile, are generating synthetic content — articles, images, videos, code — at a rate that dwarfs human production. This synthetic content trains the next generation of AI, which produces even more synthetic content. A feedback loop with no off switch.
The data centers powering all of this consume more electricity than France and Germany combined. They drink enough water to supply 50 million households. Communities in Arizona, Texas, and the Middle East fight legal battles over water rights against tech companies. A new class of e-waste — mountains of 3-year-old server racks containing rare earth minerals — piles up in developing countries.
And here is the uncomfortable truth: the overwhelming majority of the data being stored — the doorbell footage of empty streets, the duplicate backups, the AI-generated content that no human ever sees, the genomic sequences sitting in cold storage — serves no one.
This is not science fiction. Every element of this scenario is a straight-line projection from current trends.

What can actually be done?
Identifying the problem is the easy part. Proposing solutions — realistic ones — is harder. But there are avenues, and some are already being explored.
Regulatory frameworks are emerging. The EU’s Energy Efficiency Directive now requires large data centers to report energy and water consumption metrics, with minimum performance standards expected by 2026. The GDPR’s data minimization principle — the idea that you should only collect what you actually need — is a legal framework that, if enforced aggressively, could transform corporate data practices. The Maryland Online Data Privacy Act takes this further, requiring businesses to collect only data that is strictly necessary and proportionate. In Europe, the Climate Neutral Data Centre Pact commits over 100 operators to carbon-free energy and water conservation targets. Germany now requires new data centers to recover waste heat.
The concept of “digital sobriety” — la sobriété numérique, as the French call it — is gaining traction. The Shift Project, a Paris-based climate think tank, advocates for designing intentionally leaner digital services. Not minimalism for its own sake, but a conscious decision about what is worth capturing, storing, and maintaining — and what is not.
Individual choices matter more than you think. Review your cloud storage. Delete the 4,000 blurry photos. Turn off continuous recording on cameras that do not need it. Choose services with data retention policies that actually delete things. Ask your employer why the company is paying to store data nobody has touched in five years.
And the technology sector itself needs a reckoning — not just on energy efficiency (which improves every year and gets eaten by growth every year), but on the more fundamental question: should we be building systems whose default is to record, transmit, and store everything, forever?
A closing thought
There is a concept in environmental science called the “rebound effect” — where efficiency gains get swallowed by increased consumption. We made storage cheap, so we stored everything. We made cameras small, so we put them everywhere. We made networks fast, so we streamed constantly. Each individual innovation was reasonable. The aggregate outcome is not.
The writer Steven Gonzalez Monserrate at MIT put it sharply: the cloud now has a greater carbon footprint than the airline industry. A single data center can consume the equivalent electricity of 50,000 homes.
We do not need to become digital Luddites. Data, used well, saves lives — in medicine, in climate modeling, in disaster response. But “used well” is the operative phrase. Right now, for every byte of data doing something useful, there are between four and nine bytes sitting in a server rack, consuming electricity, radiating heat, drinking water, doing nothing at all.
The world’s largest landfill is invisible. It has no smell, no trucks, no seagulls circling overhead. But it is growing faster than any physical dump ever built, and unlike plastic and concrete, its footprint compounds every second of every day.
The question is not whether we can afford to address this. It is whether we can afford not to.
This article was published by the HAIA Foundation. For more on the intersection of technology, policy, and human impact, visit our Substack.