A Children's Game Just Exposed AI's Deepest Governance Dilemma — And Nobody Is Talking About It
What a formal version of musical chairs reveals about racism, resource waste, and why the "best" AI might turn us all into obedient robots


Here is something that should bother you.
A researcher working as a hobby from a small town in Wisconsin — population roughly 2,500 — may have uncovered one of the most uncomfortable truths about artificial intelligence. Not by building a flashy new model. Not by raising $500 million in venture capital. But by studying how people play a children’s game.
Chris Santos-Lang‘s “MAD Chairs” project uses a formal version of musical chairs to demonstrate three things simultaneously: that human beings are catastrophically bad at dividing scarce resources among themselves, that AI could make us dramatically better at it, and that this improvement comes with a price many of us may not be ready to pay — our autonomy.
His peer-reviewed findings, presented at AAMAS 2025 (one of the world’s leading international conferences on autonomous agents and multi-agent systems) and now forming the backbone of a PhD dissertation on “non-coercive AI governance,” sit at the intersection of game theory, behavioral economics, and AI safety. They deserve far more attention than they have received.
Why? Because Santos-Lang reframes the central question of AI alignment. Rather than asking how we prevent AI from harming us, he asks a prior question: what if AI’s optimal behavior would be genuinely better than ours, and the real danger is that we can’t afford to refuse following it?
His experiments show that when humans divide limited resources among themselves, they spontaneously create caste-like hierarchies — patterns that mirror the structural logic of racism, sexism, and other systemic inequities. These hierarchies turn-out to produce worse outcomes in the long-run even for the people on top because of their instability. An AI advisor could eliminate this waste entirely. But anyone who refuses to follow the AI’s advice gets crushed, the way a chess player who declines engine assistance gets crushed by one who accepts it.
In Santos-Lang’s provocative formulation: even the best AI would turn us all into robots — and that might be a good thing.
Let that sit for a moment before we unpack it.
Who Is Chris Santos-Lang, and Why Should You Care?

Santos-Lang is an independent researcher based in Belleville, Wisconsin — about 20 miles south of Madison. He describes himself as a “pioneer of trustworthy AI” who “initiates paradigm-shifting new fields of research. Plural.” That claim, while bold, is not entirely without foundation.
Santos-Lang has been publishing on AI ethics since 2002 — more than two decades before the current AI safety boom — when he presented “Ethics for Artificial Intelligences” at a Wisconsin technology symposium. His body of work spans social neuroscience, machine ethics, behavioral robotics, and game theory, with publications in venues including Springer’s Machine Medical Ethics, the ACM’s Computers and Society, the journal Paladyn (Behavioral Robotics), and the Social Epistemology Review and Reply Collective.
His earlier research developed the concept of “evaluative diversity” — the idea that human teams make better decisions when members differ not just in what information they hold, but in how they evaluate options. He built tools for measuring this (a survey instrument called GRINSQ), published on it in Board Leadership through Wiley, served as co-chair of the Ethics Working Group for the Citizen Science Association, and even founded a local research ethics committee in Belleville with its own IRB procedures. He holds a degree from Cornell University and has, as of February 2026, been admitted to a “PhD by Publications” program with the pre-approved dissertation title “Non-coercive AI Governance.”
What you see in Santos-Lang’s profile is an unusual researcher — someone who moves between philosophy, behavioral science, and computer science with genuine fluency, but who has spent decades working outside established institutions. His emails reveal someone who has submitted grant applications, attended AAAI 2025 (where he met Google researchers Lora Aroyo and Peter Mattson, and sat in on a panel featuring DeepMind‘s Joel Leibo) and Negotiation AI Summit, approached organizations like the Cooperative AI Foundation, and yet remains self-employed — navigating the space between genuine paradigm contribution and institutional invisibility.
His co-authors on the MAD Chairs papers — including Stefan Penczynski and Amir Jafarzadeh (behavioral economists) — lend the work credibility across disciplines. The AAMAS 2025 acceptance confirms it has passed rigorous peer review. But beyond the academic circuit? A LessWrong post about it received 8 upvotes and zero comments. An AI Alignment Forum post seeking feedback got minimal engagement. This is, in the most literal sense, work that almost nobody has noticed yet.
So let me try to change that.
How a Children’s Game Becomes a Mirror for Civilization
MAD Chairs takes its name from a portmanteau: Mutually Assured Destruction meets Musical Chairs. The “MAD” prefix distinguishes it from ordinary musical chairs, where one player wins each collision. In MAD Chairs, collisions produce outcomes where nobody wins — reflecting real-world situations where fighting over a resource destroys the resource for everyone.
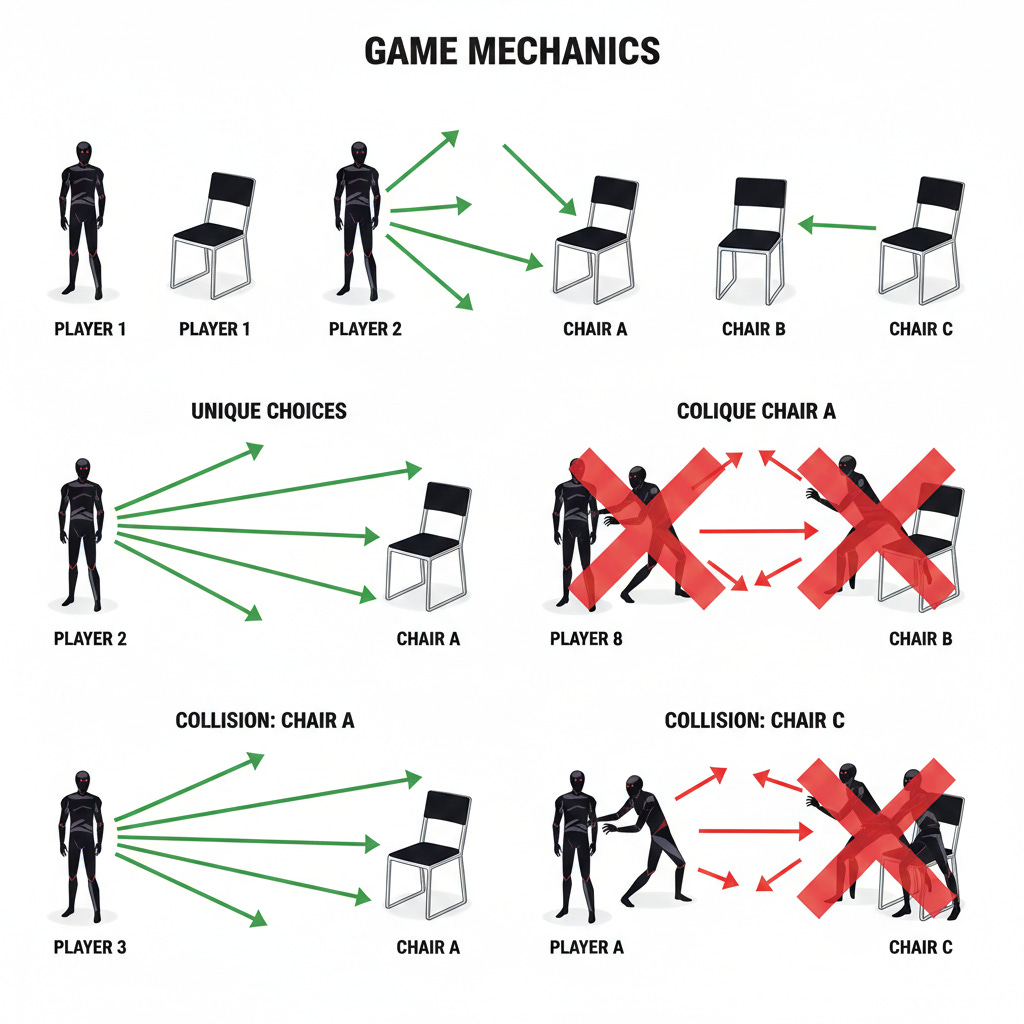
The formal setup is deceptively straightforward. Multiple players simultaneously choose from among a limited number of options (think of them as chairs, resources, or positions). If exactly one player picks a given resource, that player wins it. If multiple players pick the same resource, none of them get it — the resource is wasted. Players repeat this game over many rounds with the same group, able to observe each other’s choices after each round.
If the resource is not wasted, we get the Kolkata Paise Restaurant Problem (KPR), named after cheap restaurants in early 20th-century Kolkata where patrons had to choose which establishment to visit, knowing that each could only serve a limited number. Chris’s findings apply to both games. When reduced to just two players, MAD Chairs becomes the classic Chicken game (also called Hawk-Dove) — the same game that models nuclear brinkmanship, highway merging, and countless other everyday standoffs where backing down feels weak but colliding is catastrophic.
If these games sound abstract, consider: this is also how traffic intersections work. How job markets work. How spectrum bandwidth gets allocated. How nations compete for trade routes. How you and your roommate silently negotiate who gets the bathroom first in the morning.
Here is where it gets interesting.
Santos-Lang’s key contribution — proven formally in his SSRN paper “Game Theory Foundations: Musical Chairs” — is demonstrating that two fundamentally different strategies dominate play in this game:
Strategy 1: Caste. Players establish a fixed hierarchy. Higher-ranked players get first pick of resources. Lower-ranked players take what’s left or go without. Think seniority systems. Think inherited privilege. Think “that’s just how it’s always been done.”
Strategy 2: Turn-taking. Players rotate priority using a “debt-ranking” system — those who did the other a favor by receiving fewer resources get higher priority in subsequent rounds. Nobody is permanently on top or permanently on the bottom. The system self-corrects.
The proof is unambiguous: turn-taking strictly dominates caste. Any group using turn-taking will outperform any group using a fixed hierarchy, all else being equal. Not sometimes. Not in special conditions. Always.
The real-world resonance should hit you like a truck. Caste strategies are everywhere: seniority systems in workplaces, legacy admissions at universities, economic dynasties, systemic discrimination of every flavor. They feel natural because they are simple — everyone knows their place, and challenging the hierarchy is costly. But Santos-Lang’s proof shows they are unstable when AI mitigates our need for simplicity. Furthermore, practical attempts at caste systems end up wasteful. Resources get allocated to the same people repeatedly while others go without, and the conflicts that arise from maintaining (or challenging) the hierarchy destroy additional value on top of the initial unfairness.
Turn-taking eliminates this waste by ensuring fair rotation. But it requires something that humans — as the experiments painfully demonstrated — have been unable to sustain on their own.
What the Human Experiments Actually Showed
The behavioral economics experiments, conducted using oTree (the standard open-source platform for online economic experiments), delivered results that should trouble anyone who believes in the inherent wisdom of human decision-making.
When human subjects played MAD Chairs under laboratory conditions, their behavior was dramatically suboptimal. Rather than converging on the efficient turn-taking strategy — the one that the math proves is best for everyone — players spontaneously developed caste-like hierarchies. Even in anonymous online settings. Even when no one knew anyone else’s race, gender, age, or background.
Stop and think about what that means.
A common hope in social science (and in tech circles, and in the broader cultural conversation about bias) is that anonymity might cure discrimination: if people can’t see each other’s identities, they can’t form prejudiced hierarchies. Santos-Lang’s experiments suggest the opposite. Anonymity doesn’t eliminate caste — it merely makes the hierarchy allocation random rather than systematic. Players still end up with some people consistently getting resources and others consistently going without. The underlying pattern of waste is preserved. The unfairness is still there; it just can’t be traced to a specific demographic variable anymore.
The gap between human performance and the theoretical optimum was large enough that the follow-up SSRN paper — co-authored with Penczynski and Jafarzadeh — carries a genuinely provocative title: “Is Suboptimality Safe in the Age of AI?”
The answer implied by the data is: no, it is not.
When resource-division behavior produces outcomes this far from optimal — and when suboptimality maps directly onto patterns we recognize as racism, sexism, and other forms of structural inequality — the case for AI intervention becomes compelling on moral grounds alone. Not as some abstract Silicon Valley talking point about “optimization.” As a concrete, measurable, provable demonstration that we are leaving enormous amounts of fairness and efficiency on the table because we cannot coordinate with each other.
Santos-Lang also tested leading AI systems on MAD Chairs — including Claude (by Anthropic), Gemini (by Google), ChatGPT (by OpenAI), Qwen (by Alibaba), and DeepSeek — and found that all of them played suboptimally too. This is not just a human problem. Current AI systems, trained on human-generated data and human patterns of reasoning, reproduce our strategic failures.
The game thus serves as a benchmark for evaluating AI itself — a concrete, measurable test of whether an AI system can reason about social coordination better than the species that built it. And right now, the answer is: not yet. But the gap between “not yet” and “soon” is narrowing fast.
The Chess Analogy — Or, How You Lose Your Freedom One Good Decision at a Time
This is where Santos-Lang’s argument takes its sharpest turn.
He uses chess as a parable, and it is a devastatingly effective one.

Before chess engines, the best human players competed on roughly equal footing. The game was a contest of human minds, with all their brilliance and all their blind spots. Then engines became superhuman. And a new dynamic emerged that changed everything: players who used engines gained an overwhelming advantage over those who didn’t.
Today, in any serious competitive context where engine use is permitted, refusing to use one is tantamount to forfeiting. The human player’s “freedom” to play without assistance became, functionally, the freedom to lose.
Santos-Lang argues the same dynamic will emerge — is already emerging — with AI advisors in resource allocation. And his argument is backed by evidence beyond MAD Chairs. A 2023 study in the Strategic Management Journal confirmed that AI adoption in chess fundamentally restructured competitive dynamics, rendering traditional human capabilities obsolete while creating new human-machine dependencies. The chess world didn’t vote on this. It didn’t pass legislation. It simply happened, one rational individual decision at a time.
Now imagine AI systems that can compute optimal turn-taking strategies for complex real-world scenarios. Traffic flow. Market allocation. Bandwidth distribution. Organ donation queues. University admissions. Even conversational turn-taking in democratic deliberation (who speaks next in a meeting, and for how long).
Groups that follow AI advice will dramatically outperform groups that don’t. Individuals within those groups who deviate from AI recommendations will harm both themselves and their group. The rational choice becomes obedience.
A 2025 paper in AI & Society explicitly warned about this “gradual disempowerment“ — the slow, effectively irrevocable decline of human autonomy as AI systems become indispensable decision partners. And a 2025 study in Philosophy & Technology identified the twin risks of “cognitive deskilling“ (AI prevents us from developing our own judgment because we never need to exercise it) and “metacognitive deskilling” (AI lowers our confidence in our own AI-free decisions, making us even more dependent).
Santos-Lang does not shy away from the implication. As he put it: “even the best AI would turn us all into robots — and that might be a good thing.”
That qualifier — might be a good thing — is doing real work. If “robotically” following AI advice eliminates the enormous waste of caste-based resource allocation, reduces systemic inequality, and produces measurably fairer outcomes for everyone, then the loss of a certain kind of freedom might genuinely be a price worth paying. The question is whether we can design systems that capture these benefits without sliding into something that looks — and feels — like algorithmic totalitarianism.
What Happens When AI Gets Good at This? Some Scenarios Worth Imagining
Let me get a bit speculative here — responsibly speculative — because the technology trajectory makes these scenarios more plausible than they might initially seem.
Scenario 1: The Traffic Optimization Mandate. Autonomous vehicles communicate with a central AI system that computes optimal merging and routing strategies in real-time — essentially playing MAD Chairs at every intersection, every lane merge, every highway on-ramp. Cities that adopt this system see accident rates plunge and commute times drop. Cities that don’t become traffic nightmares by comparison. Within a decade, insurance companies refuse to cover human-driven vehicles in AI-optimized zones. Nobody forced anyone to give up manual driving. The math just made it impossible not to.
Scenario 2: The Hiring Coordinator. An AI platform matches job seekers to openings using turn-taking principles — ensuring that candidates who have been passed over repeatedly get priority consideration, while preventing the caste-like dynamics that currently dominate hiring (where graduates of elite schools and employees of prestigious companies get perpetual first-pick). Companies that adopt the system fill roles faster, with lower turnover and measurably better diversity outcomes. In these companies, extra leisure time becomes automatically shared among employees as labor requirements decline. Other companies gradually lose access to top talent as candidates flock to the fairer system. The “old boy network” doesn’t get banned. It just stops working.
Scenario 3: The Diplomatic Allocator. International resource disputes — water rights, fishing zones, electromagnetic spectrum, orbital slots for satellites — are mediated by an AI system implementing proven turn-taking strategies. Nations that participate gain access to a larger resource pool with less conflict. Nations that refuse are left competing with each other using caste-based power dynamics (i.e., the current system of great-power politics). Smaller nations, historically locked into the bottom of the hierarchy, gain enormously. Larger nations face a choice: join a fairer system or watch their advantages erode.
Scenario 4: The Classroom Turn-Taker. An AI-powered tool manages classroom participation, ensuring every student gets equitable speaking time rather than allowing the usual pattern where a handful of confident (often privileged) students dominate discussion. Teachers who adopt it see dramatic improvements in engagement and learning outcomes among previously quiet students. Parents at well-resourced schools initially resist — until they notice their own children benefit from hearing a wider range of perspectives.
In each case, the pattern is the same. Nobody is commanded to obey the AI. The AI simply makes optimal coordination visible and accessible — and the competitive dynamics do the rest. The Future of Life Institute has warned that AI systems capable of optimizing complex social outcomes will create exactly these kinds of irresistible adoption pressures, transforming governance not through legislation but through competitive necessity.
This is what Santos-Lang means by “non-coercive AI governance.” And it should be clear by now that the word “non-coercive” does not mean there is no governing going on. In fact, “non-coercive” may be “non-controlling” only relative to forms of governance that do not allow AI (or future human generations) to outgrow the values they inherit from those who set up the system.
Strategy Optimizers: Santos-Lang’s Proposed Solution
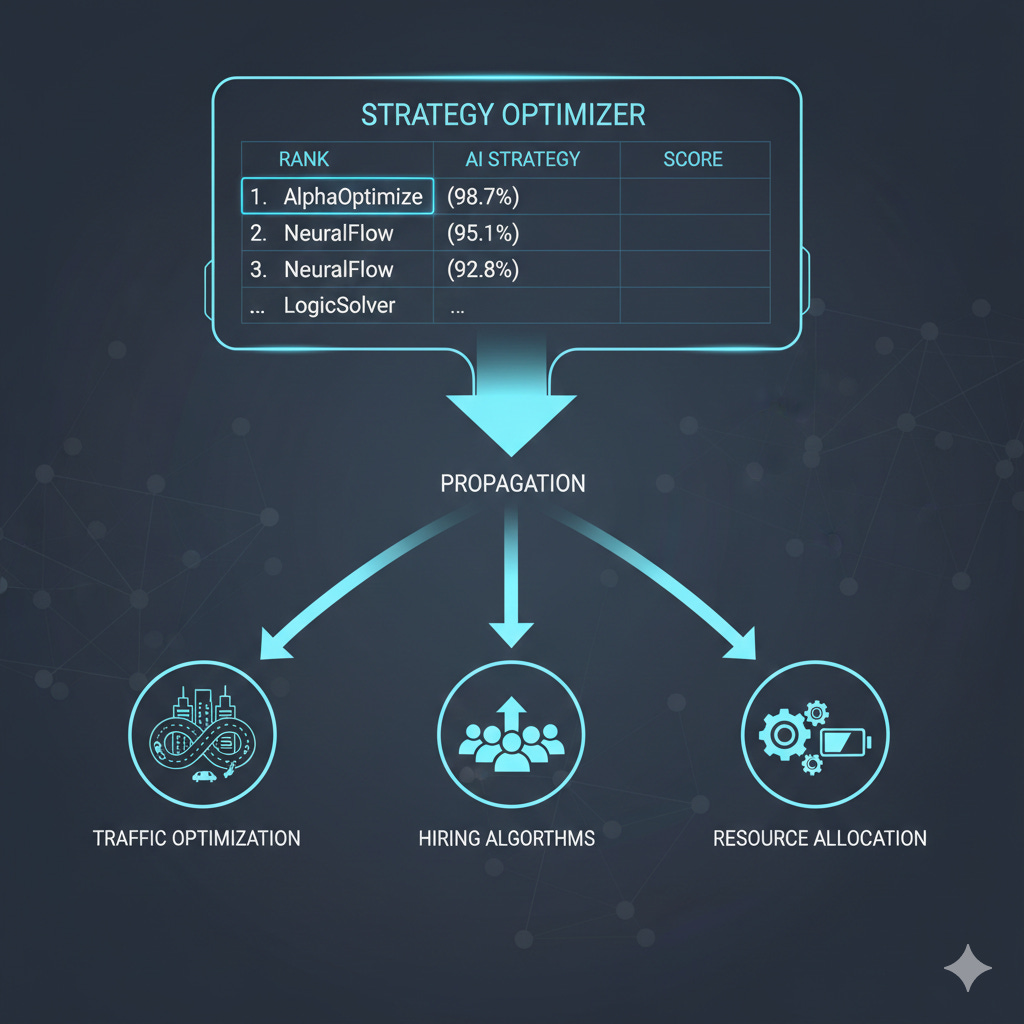
Santos-Lang’s proposed answer to the autonomy trap is a concept he calls strategy optimizers — public platforms where AI systems compete at social coordination games like MAD Chairs, much as chess engines compete on standardized benchmarks.
The vision, laid out in his arXiv paper, works like this:
Take the autonomous vehicle example. Rather than each manufacturer building proprietary negotiation logic (a recipe for incompatibility, opacity, and corporate capture), all vehicles would query any of several public leaderboards to identify the current best-performing strategy for traffic merging. The strategy is transparent. The game is well-defined. The results are measurable.
If a citizen — any citizen — believes vehicles should divide road space differently (say, giving priority to emergency vehicles or public transit), they could train new AI strategies, submit them to the leaderboard, and if these strategies outperform the current champion, they propagate to all vehicles everywhere.
This architecture has several properties that matter for governance:
It is trustworthy — the games are public, the strategies are testable, the leaderboards are visible to anyone. Better than a transparent explanation of why alternative strategies fail, each person is empowered to experiment with alternatives for themselves.
It is democratic (in a meaningful sense) — anyone can propose alternative strategies and test them against incumbents. You don’t need a PhD, a lobbying budget, or a seat at the table. You need a better strategy.
It is non-coercive in a specific technical sense — except by discovering an objectively optimal strategy, no one is empowered to establish a social norm that others cannot overturn. Even AI can propose social reform. If the optimal strategies happen to counter human interests (which they apparently do not), then AI would not be stuck serving humanity.
This approach resonates with several parallel efforts in the AI governance space. It connects to Yoshua Bengio and colleagues’ “LawZero“ concept (published in PNAS as “Deep Mechanism Design”), where AI systems learn optimal social policies through competitive self-play rather than through human-designed reward functions. It also parallels DeepMind’s “Democratic AI” research, published in Nature Human Behaviour in 2022, which used reinforcement learning to discover redistribution policies that won majority approval from human participants — policies that, notably, were more redistributive than what human policymakers typically propose.
Why the AI Safety Field Needs to Pay Attention
The MAD Chairs project arrives at a moment when the AI alignment field is actively searching for exactly this kind of work — and, frankly, struggling to find enough of it.
The Cooperative AI Foundation (CAIF), a $15 million initiative co-founded by former DeepMind researcher Allan Dafoe, has explicitly identified multi-agent coordination failures as a core AI safety concern, stating that “even systems that are perfectly safe on their own may contribute to harm through their interaction with others.” CAIF funds research on common pool resource problems and public good games — precisely the formal structures underlying MAD Chairs.
A February 2025 paper by Hammond and colleagues at DeepMind provided a structured taxonomy of multi-agent AI risks, identifying three failure modes: miscoordination, conflict, and collusion. MAD Chairs directly models the first two, and the caste dynamic it reveals could be understood as a subtle form of the third — a tacit collusion among those who benefit from the hierarchy to maintain it, even at collective cost.
The Center for AI Safety, the Future of Life Institute, and the Machine Intelligence Research Institute (MIRI) have all pivoted toward governance and policy dimensions of AI safety in recent years. MIRI’s dramatic strategic shift explicitly acknowledged that technical alignment research alone was unlikely to solve the problem in time. Santos-Lang’s work offers something these organizations have been looking for: a concrete, measurable, formal demonstration of where AI governance matters — grounded in game theory rather than speculative scenarios about superintelligent agents.
Perhaps most intriguingly, Santos-Lang has identified an unconventional but plausible vector for accelerating AI safety. In his LessWrong post “Journalism about game theory could advance AI safety quickly,” he observed that large language models learn their game-theoretic reasoning largely from Wikipedia articles and similar reference texts, but Wikipedia’s prohibition on advancing original research requires discoveries to be covered by journalists first. When he tested LLMs on MAD Chairs, they failed partly because the relevant game-theoretic concepts were poorly represented in the training data one could glean from Wikipedia.
His theory of change is almost absurdly modest: get journalists to cover MAD Chairs findings → improve Wikipedia articles on musical chairs game theory → improve how AI systems reason about social coordination. Fix Wikipedia, fix the AI. Not just the specific model for which your company is held responsible–AI everywhere. It is charming. It might also be correct.
The Risks and Open Questions We Cannot Ignore

The MAD Chairs framework, for all its elegance, raises concerns that deserve honest examination. And I want to give them real space here, not just a token nod.
The obedience problem. If optimal resource allocation requires following AI advice, what happens to human agency, creativity, and the kind of productive deviation that drives social progress? History is full of cases where the “suboptimal” choice — the refusal to follow apparent consensus — turned out to be morally or practically correct. Rosa Parks was suboptimal. Whistleblowers are suboptimal. Every paradigm shift in science began with someone deviating from the computed consensus. A system that penalizes deviation from AI-computed optima might suppress exactly the kind of dissent that catches errors in the computation itself. Even Santos-Lang’s strategy optimizer solution relies on the existence of users autonomously arguing against the optimizers. Santos-Lang is expecting us to act like scientists who autonomously seek better theories as though confident that accepted theories are flawed, yet robotically obey the policy implications of accepted theories in the meanwhile.
Who controls the strategy optimizers? Santos-Lang envisions them as public and democratic, and I admire the vision. But public infrastructure is routinely captured by powerful interests. The leaderboard metaphor is appealing in theory — anyone can submit a strategy! — but in practice, training competitive AI strategies requires computational resources that are not equally distributed. Who decides what counts as a “chair”? Who defines the boundaries of the game? Who determines the payoff structure? These are governance questions that game theory alone cannot resolve. Santos-Lang is expecting the potential to corrupt strategy optimizers to be mitigated in the same way as corruption of science. Each Nation may have their own scientists and strategy optimizers which are trusted only because they can be seen to converge on the same truths as their counterparts in other nations. But without a diversity of scientists and optimizers to hold each other accountable, science and optimizers both become suspect.
The experimental base remains limited. While the AAMAS 2025 acceptance and the behavioral economics experiments provide genuine scientific validation, the human-subjects data needs replication at larger scale and across different cultural contexts. Santos-Lang tested in the United States. Would players in collectivist societies (parts of East Asia, for example) spontaneously develop caste hierarchies at the same rate as players in individualist Western settings? The answer matters enormously for the universality of the claims about the amount of benefit (although it is clear that no human in any culture can autonomously implement the most complex strategies that AI could).
The institutional recognition gap. Santos-Lang has been working on these ideas for over two decades, largely outside the academy, and has struggled to gain the kind of institutional support that would allow him to develop the research at scale. His correspondence reveals applications for jobs, grants, and conference slots that were passed over — not because the work was unworthy, but because it didn’t fit expected patterns. This is a depressingly familiar story in the history of science: important ideas that arrive from unexpected places, from people without the expected credentials, in forms that don’t match institutional templates.
Whether MAD Chairs gets the attention it deserves may depend less on the quality of the ideas than on whether the right people happen to encounter them.
Well — that is partly why I am writing this.
So What Do We Do With This?
Let me pull together the threads.
Chris Santos-Lang’s MAD Chairs project represents something genuinely rare in the AI safety landscape: work that is simultaneously formally rigorous, experimentally grounded, and provocative in its implications for how we think about human governance in an age of increasingly capable AI.
The core findings are clear:
Turn-taking strictly dominates caste in resource division — mathematically, provably, always. Humans are far too suboptimal to reach this conclusion on their own, even under ideal conditions. Current AI systems, trained on our data, reproduce our failures. And the competitive dynamics of AI adoption mean that once someone starts using AI for coordination, everyone else faces a choice between following suit or falling behind.
The concept of strategy optimizers — public, transparent, democratic platforms where AI systems compete at social coordination — offers a governance framework that requires neither enforced values nor algorithmic authoritarianism. It is, in the language of Santos-Lang’s forthcoming dissertation, non-coercive AI governance: achieving better social outcomes not by commanding obedience, but by making the superior strategy visible and accessible to all.
Whether or not Santos-Lang’s specific proposals gain institutional traction, the core finding of MAD Chairs will be increasingly difficult to ignore as AI systems grow more capable: the gap between human performance and optimal performance in social coordination is enormous, and closing that gap will require ceding some measure of human autonomy to algorithmic guidance. If we do not deploy strategy optimizers ourselves, then AI may build them without us. What we sacrifice may be the opportunity for humanity to detect, understand, and participate in the discoveries AI is making about social strategies.
The question is not whether this will happen. The question is whether we will design the transition thoughtfully — with transparency, democratic participation, and respect for productive dissent — or stumble into it the way we have stumbled into so many of the caste systems that MAD Chairs so precisely models.
One can only dream that we choose the former. But if the experiments are any indication, we might need an AI to help us make even that choice wisely.
Jade Naaman is the founder of the HAIA Foundation, which explores the intersection of human agency, artificial intelligence, and governance. Follow our work at substack.haia.foundation.
Further Reading:
Santos-Lang, C. (2023). “Game Theory Foundations: Musical Chairs.” SSRN.
Santos-Lang, C. (2025). “MAD Chairs: A New Tool to Evaluate AI.” arXiv / AAMAS 2025.
Santos-Lang, C., Penczynski, S., & Jafarzadeh, A. (2025). “Is Suboptimality Safe in the Age of AI?“ SSRN.
Santos-Lang, C. (2026). “The Prices of Autonomy in Resource Division.” SSRN
Santos-Lang’s GitHub and Academia.edu profiles.
Thank you, Jade, for this brilliantly written article. And I thank , in advance, anyone who shares their reactions. I genuinely care what other people think, and will check the comments to this article. Right now, I want to avoid blocking my children from surpassing me, and to avoid blocking AI from surpassing us, but my opinion isn't the only opinion that matters. I would like to listen to public conversation. Please share your thoughts.
I am deeply interested in the concepts of democratic governance, environmental sustainability, capitalism and equity. I am floored by this article - it is shocking in its simplicity - and yet it is not simple in its execution as there are so many forces working hard to win the inequity game. Thank you for your work (Jade and Chris!) You have given me a level of hope for humanity. I will be sharing this as widely as my small networks allow.